
I’m a huge fan of Go’s table-driven tests. They’re really well-suited for behavioural testing, which we discussed before, and they make writing tests quite easy.
As with the previous post in this series, this was written to prepare for a learning session on tests at work; the content here is a collection of suggestions and observations based on how our team was writing tests. Maybe you’ll find it useful too; maybe you won’t.
I make no apologies for this post’s title.
Tools exist to generate the skeleton of a table-driven test automatically.
If you’re using Visual Studio Code for Go development (and according to the most recent
Go Developer Survey, chances are good that you do),
the Go extension adds a convenient Generate Unit Tests for Function option to the Right-Click
menu. This functionality is powered by the gotests tool,
which can also be integrated into your alternative editor of choice.
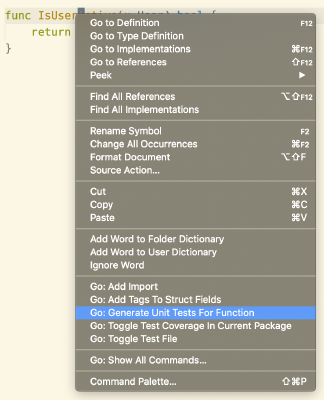
Selecting this results in a test file being created (if necessary) and an empty test table generated for the function.
func TestIsUserActive(t *testing.T) {
type args struct {
u User
}
tests := []struct {
name string
args args
want bool
}{
// TODO: Add test cases.
}
for _, tt := range tests {
t.Run(tt.name, func(t *testing.T) {
if got := IsUserActive(tt.args.u); got != tt.want {
t.Errorf("IsUserActive() = %v, want %v", got, tt.want)
}
})
}
}
Note the use of an argument struct here - we’ll revisit this later on.
This isn’t limited to just functions, too - methods on structs with fields are handled nicely as well1:
type User struct {
Name string
EmailAddress string
Birthday time.Time // TODO: display on profile.
}
// CalculateAge calculates the user's age.
func (u User) CalculateAge() int {
// Implementation here.
}
func TestUser_CalculateAge(t *testing.T) {
type fields struct {
Name string
EmailAddress string
Birthday time.Time
}
tests := []struct {
name string
fields fields
want int
}{
// TODO: Add test cases.
}
for _, tt := range tests {
t.Run(tt.name, func(t *testing.T) {
u := User{
Name: tt.fields.Name,
EmailAddress: tt.fields.EmailAddress,
Birthday: tt.fields.Birthday,
}
if got := u.CalculateAge(); !reflect.DeepEqual(got, tt.want) {
t.Errorf("User.CalculateAge() = %v, want %v", got, tt.want)
}
})
}
}
We now have a fields struct which lets us easily initialise the struct to be tested. If we had
arguments to the method, there’d be an args struct as well, just as we saw earlier.
This gives us a good launching point to start writing tests quickly. I use this feature all the time
to get the outline up, then make changes - we use
stretchr/testify’s assert package to do assertions, so
I’d rip out the if statement the tool generates and replace it with the appropriate calls. You
could also prune out any fields which aren’t strictly necessary - in our example here, it seems
unlikely that CalculateAge is going to use Name or EmailAddress, so you could drop them.
I’d also then parallelise the test, which brings us to our next point.
Run all your tests in parallel, if you can.
It’s a good idea in general to run tests in parallel, and by default go test will use the number
of cores available to do so. But tests themselves won’t magically run in parallel - you need to add
t.Parallel() to them.
This is pretty easy for a regular test - just throw it at the start of the test func - but for a table-driven one there’s a little bit more that you have to do:
|
|
We have to add t.Parallel() to the overall test function itself (line 2) as well as each
sub-test (line 17). More importantly, though, we also need to alias tt to itself on line 19 -
otherwise not all of the tests will actually get run.
This section of the Go wiki
explains more.
It’s also worth noting that not all tests can be run in parallel; if your test is for code that needs to rely on shared state and which modifies that state (an external database or file, some global variable, etc.), it’s likely not going to work in parallel. This is a code smell, though, and running tests in parallel can help you find places where this is the case when it wasn’t intended and hopefully fix the issue.
Consider using a map instead of a slice for the table.
A team mate actually suggested doing this some time back, though it didn’t quite stick. Dave Cheney’s post about table-driven tests does suggest using maps, so it’s not entirely unheard of, but it does seem quite uncommon in the Go ecosystem as a whole; most tests use slices instead.
The benefits of using a map instead of a slice are that you can drop the name field from the test
struct (since the map key can be used for it instead) and that tests are no longer run in a fixed
order since map iteration order is undefined. This is a good thing since the order in which your
tests run shouldn’t affect whether or not they pass; it’s a code smell if it does.
It’s really hard to shake the habit of using a slice, though. It being the default means it’ll likely live on, which is fine too.
Name your tests using a description of the expected behaviour.
I’ve seen tests with names like correct behavior, error, and success. These names don’t really
say anything about what exactly is being tested - they’re too generic and require you to look at the
exact arguments and expectations to figure it out.
Naming tests in a more descriptive way - describing what the inputs/preconditions are, and what the expected result/behaviour is - lets you read the name of the test and understand everything. The pitfall here is that this is similar to a comment: if it’s not kept up to date, it’s useless.
One way to think about this is returns x given y or does x when y, where x and y are also
high-level descriptions and not the literal values.
returns an error when the user is not found is better than user not found. sends an email on successful registration is better than successful.
Avoid having test set-up outside of the test itself.
In my opinion, one of the biggest benefits of a table-driven test is that you can see everything related to a particular test instance in a single place. This is lost if you end up having set-up outside the test itself, though.
One of the biggest reasons I’d end up doing or seeing this happen early on was that an argument or field value needed to be an interface or pointer, and you couldn’t just initialise those in-line:
// Assuming a Nickname *string field on our user...
type fields struct {
Nickname *string
}
tests := []struct {
name string
fields fields
want bool
}{
{
"returns true if a nickname is set",
fields{
Nickname: &"Ayulin", // This isn't valid!
},
true,
},
}
So we’d end up defining the value before the test table instead.
nickname := "Ayulin"
tests := []struct {
name string
fields fields
want bool
}{
{
"returns true if the user has a nickname set",
fields{
Nickname: &nickname,
},
true,
},
}
You’d see similar with mocked interfaces, too - the mock is declared above the start of the table and referenced inside.
This now requires us to bounce back and forth between the test instance in the table and the code above the table, though, and that “foreword” section often ends up pretty long and cluttered. You can get around this and do everything in-line by using anonymous functions instead:
tests := []struct {
name string
fields fields
want bool
}{
{
"returns true if the user has a nickname set",
fields{
Nickname: func() *string { s := "Ayulin"; return &s },
},
true,
},
}
Longer, more involved initialisations are a lot more readable if they’re split onto multiple lines.
This technique keeps everything in one place - the test is entirely self-contained and doesn’t require referencing things defined elsewhere. The downside here is that the test instance itself ends up being longer (and some would say more cluttered), especially if there’re mock definitions being set up in-line. I think this is still preferable to having all of the clutter in one non-segregated place; you have proximity here, which is better than everything being put in one big, unrelated chunk at the start of the test function.
The next topic is pretty similar.
Avoid defining helper functions for tests, unless you’re in a test package.
Helper functions can be useful to DRY up some of the stuff you’d do for test set-up, but they also end up polluting the namespace of your package. Since they’re private this isn’t an issue for your callers, but it’s still not great; I’ve seen examples where core business logic relied on a helper function defined in a test file.
The better solution is to define the helper as an anonymous function as part of your test function itself. This is an exception to the previous point about not putting stuff in the preamble of your test function, before the table.
That is, instead of:
func initMockUserDatabase(<some parameters>) user.Database {
// <implementation to prepare and return a mock>
}
Put this inside the test function instead:
func TestGateway_GetUser(t *testing.T) {
initMockUserDatabase := func(<some parameters>) user.Database {
// <implementation to prepare and return a mock>
}
// Test tables below.
}
This does somewhat go against what we just said, about doing everything within the test instance itself, though for cases where a helper does make things clearer this strategy can be useful.
Of course, if you’re operating within a separate _test package, this isn’t really necessary.
Use structs to handle both arguments and expectations.
We saw that gotests creates an args struct for method/function arguments automatically, though
it doesn’t create one for expected return values. I think doing so is a little clearer and better
than using the want prefix that gets used quite frequently.
So turn this:
tests := []struct {
name string
args
want User
wantErr bool
}{}
Into:
type want struct {
user User
err bool
}
tests := []struct {
name string
args
want
}{}
With just a single return value this isn’t too useful, though if you happen to have multiple or want
to be more descriptive about what the return value is, this helps there. I’m also not a fan in
general of the want prefix. YMMV.
Don’t check error messages unless they’re part of your contract (and avoid having that too!)
You might have noticed that, when generating a test table for a function or method that returns an
error, gotests will use a Boolean wantErr field in the test struct and not an error itself or
even a string for the expected error message. This is good. Don’t check that a specific error
message is being returned.
If you’re checking that the error returned has a specific error message, that’s an indication that the test is overfitting to the implementation - unless you actually need to return specific errors as part of your code’s contract, you can do without these checks. It’s also better to not have that even be part of your contract to begin with - code shouldn’t be introspecting error messages at all.
If you really need to be able to have code take different actions depending on the sort of error
that was encountered, keep using a Boolean wantErr and instead introduce an “error checker” func
that’ll check if the error implements a specific interface:
type retryable interface {
IsRetryable() bool
}
func IsRetryable(err error) bool {
re, ok := err.(retryable)
return ok && re.IsRetryable()
}
// ...
type want struct {
err bool
isCorrectErr func(error) bool
}
tests := []struct{
name string
args
want
}{
{
"returns a retryable error if blah",
args{
// something or another
},
want{
err: true,
isCorrectErr: IsRetryable,
},
},
}
This type of test still verifies that the correct behaviour is met - the code is returning the correct sort of error under certain circumstances - while not coupling it to an error message that can change frequently. Dave Cheney goes into the idea of using interfaces for error behaviours in more detail here.
-
If you were actually implementing this method, you’d have to have some sort of way to stub out the clock in order to actually test this; the signature would probably look different as a result. This is just an example, though (and honestly, I forgot about that complication when initially writing it), so we’re not doing that here. ↩︎